The Ultimate Local LLM Platform
Train, run, and chat with local LLM models on your device with complete privacy and control.
Local
LLM
AI Power in Your Hands
Kolosal AI puts the full potential of large language models on your device with a lightweight, open-source application that prioritizes speed, privacy, and customization.
Experience the power of local LLM models with an intuitive chat interface designed for speed and efficiency.
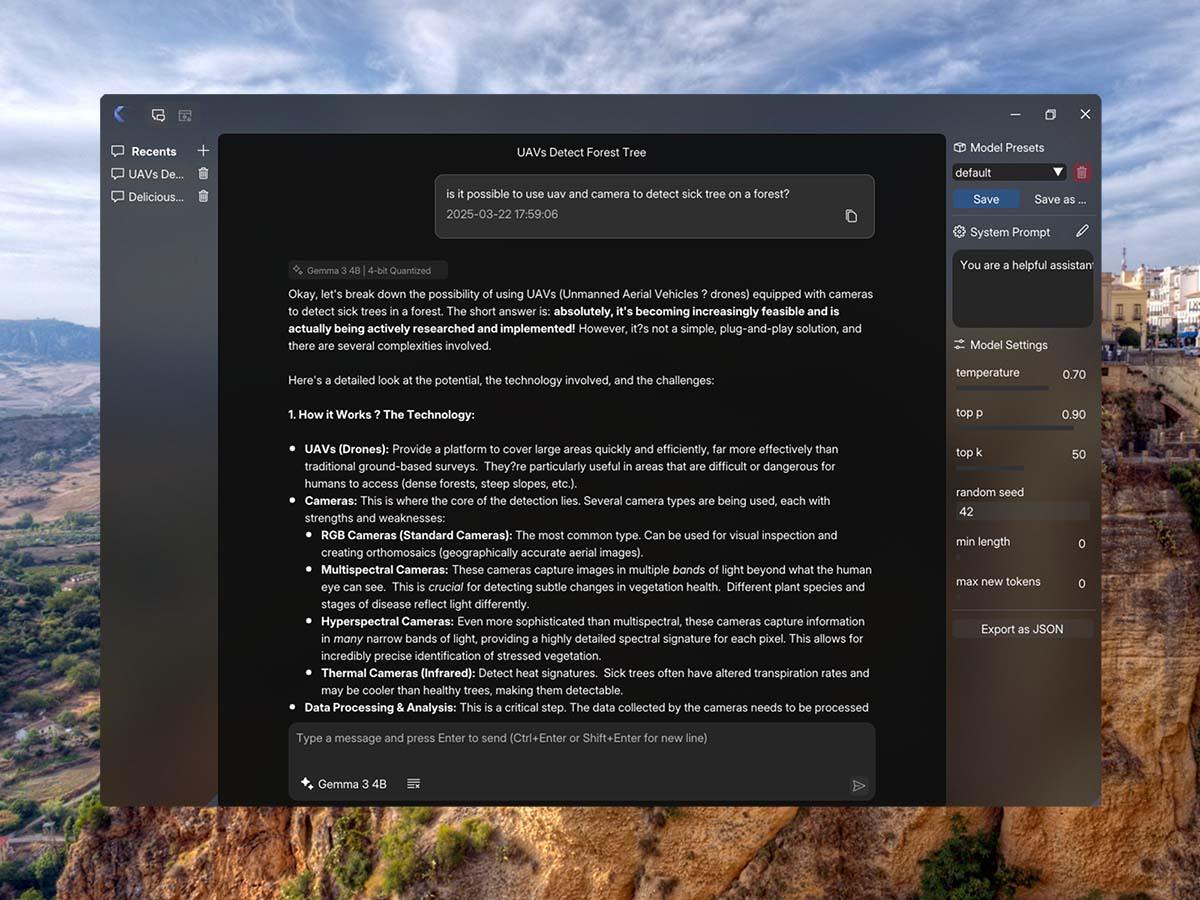
Why Choose Our Local LLM Platform
No cloud dependencies, no subscriptions—just powerful local LLM technology at your fingertips.
Open source
Powerful
100% local
Lightweight
Local LLM FAQs
Everything you need to know about Kolosal AI and running local LLM models on your device.