

Benchmarking the Genta Inference Engine: A Leap in Performance and Efficiency
Introduction
In the realm of AI and machine learning, the efficiency and speed of inference engines are critical to the success of various applications. Genta Technology has developed the Genta Inference Engine, an advanced system that promises superior performance, security, and rapid deployment capabilities. This article benchmarks the Genta Inference Engine against other notable solutions like vLLM and Hugging Face (HF), showcasing its impressive capabilities.
Benchmark Results Overview
We conducted comprehensive benchmarks to compare the performance of the Genta Inference Engine with vLLM and HF on NVidia L40s. The results are summarized below:
vLLM Benchmark
Throughput: 18.85 requests/s, 2413.085 tokens/s (Input Tokens + Generated Tokens)
Performance Issues: Encountered KV cache space limitations leading to preemptions, which affected end-to-end performance.
Hugging Face (HF) Benchmark
Throughput: 8.10 requests/s, 2073.34 tokens/s (Input Tokens + Generated Tokens)
Genta Inference Engine Benchmark
Genta Inference Engine achieved a remarkable result at throughput, latency, and memory usage compared to vLLM and TGI.
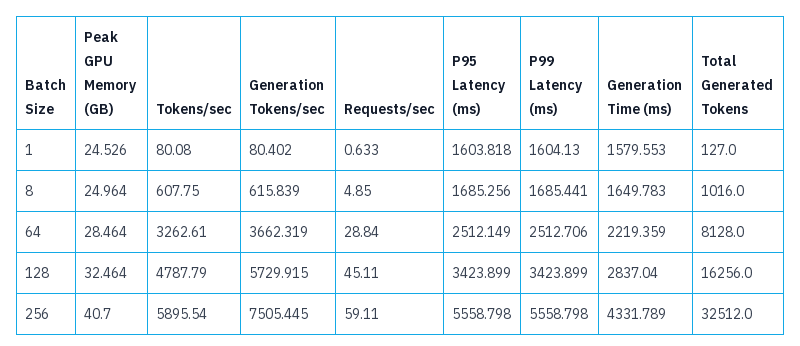
Figure 1: Genta Inference Engine Benchmark Result
Tokens/sec
Definition: This metric measures the number of tokens processed per second by the inference engine. It includes both the input tokens (the tokens fed into the model) and the output tokens (the tokens generated by the model as a response).
Use Case: Tokens/sec gives a holistic view of the throughput of the inference engine, encompassing the entire input-output cycle.
Implications: Higher tokens/sec indicates that the engine can handle more data within a given time frame, making it suitable for scenarios requiring high throughput.
Generation Tokens/sec
Definition: This metric specifically measures the number of output tokens generated per second by the inference engine. It focuses solely on the tokens produced as a response to the input, excluding the processing of input tokens.
Use Case: Generation tokens/sec is particularly useful for evaluating the efficiency of the model's response generation capability.
Implications: Higher generation tokens/sec indicates that the engine is more efficient at generating responses, which is crucial for applications like chatbots, automated customer service, and other interactive AI systems.
Analysis
Performance and Efficiency
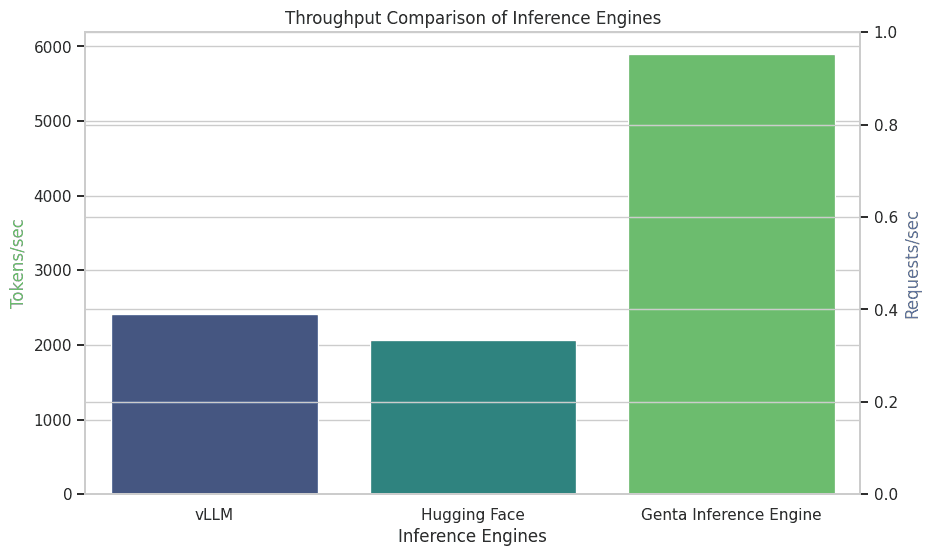
Figure 2: Throughput comparison of Genta Inference Engine, vLLM, and HF
The Genta Inference Engine demonstrates remarkable performance across various batch sizes. Even with a single batch, it achieves a tokens/sec rate of 80.08, significantly outpacing HF's throughput of 2073.34 tokens/s with batch processing. As the batch size increases, the efficiency of the Genta Inference Engine scales impressively, reaching up to 5895.54 tokens/sec with a batch size of 256. This scaling efficiency is a testament to the advanced optimization and resource management inherent in the Genta Inference Engine.
Latency
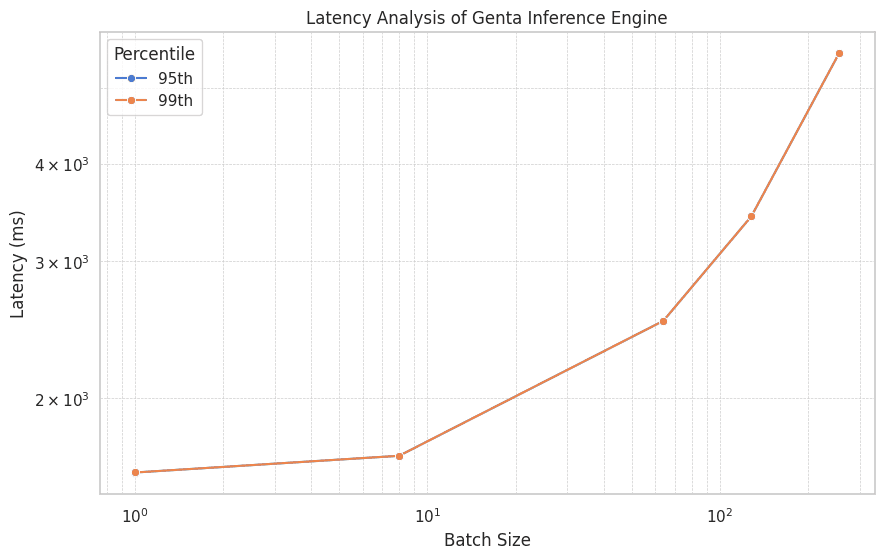
Figure 3: Latency analysis of Genta Inference Engine at different batch sizes
The latency metrics of the Genta Inference Engine are also noteworthy. With a P95 latency of 1603.818 ms for a batch size of 1, it maintains relatively low latency even as the batch size increases. The P99 latency figures follow a similar trend, ensuring consistent and reliable performance.
Memory Utilization
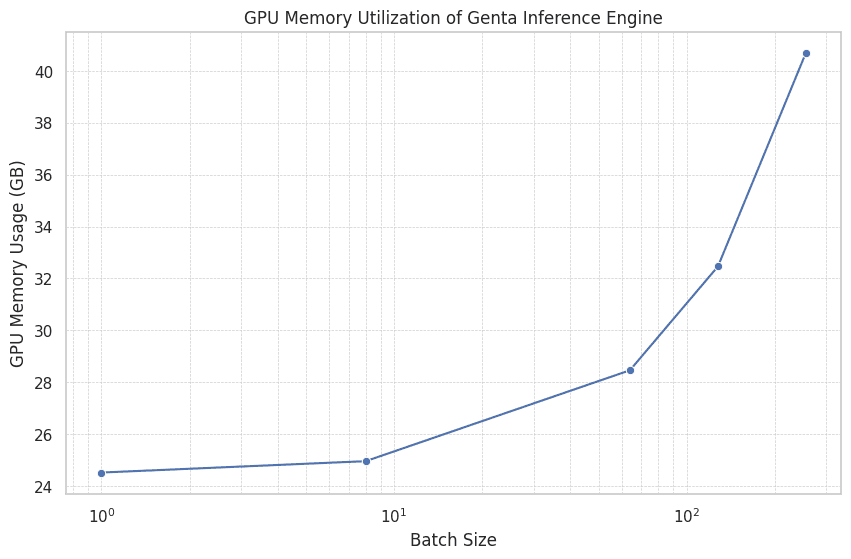
Figure 4: GPU memory utilization of Genta Inference Engine at different batch sizes
One of the key advantages of the Genta Inference Engine is its efficient GPU memory utilization. Even at higher batch sizes, it maintains manageable peak memory usage, enabling it to handle larger workloads without compromising performance or requiring excessive hardware resources.
Conclusion
The benchmark results clearly indicate that the Genta Inference Engine by Genta Technology stands out as a superior inference solution. It offers exceptional performance, scalability, and efficient resource utilization, making it an ideal choice for businesses and developers seeking to leverage advanced AI capabilities. With its faster speeds, higher security, and lightweight nature for rapid deployment, the Genta Inference Engine sets a new standard in the industry, outperforming competitors like vLLM and HF.
Genta Technology's commitment to innovation and excellence is evident in the design and performance of their inference engine, making it a game-changer in the field of AI and machine learning.